


En matière de programmation, la plupart d’entre nous écrivons du code à un niveau d’abstraction qui pourrait être celui d’un ordinateur des années 1960. L’entrée arrive, vous la traitez et vous produisez une sortie. Bien sûr, un appel à strcpy peut mieux fonctionner sur un processeur moderne que sur un ancien, mais vos algorithmes de base sont les mêmes. Mais que se passerait-il s’il existait des moyens de définir vos programmes qui fonctionneraient mieux sur du matériel moderne ? C’est ce qu’un livre pré-imprimé de [Sergey Slotin] réponses.
À titre d’exemple simple, considérons les effets de la ramification sur le pipelining. Presque tous les pipelines d’ordinateurs modernes. Autrement dit, une instruction récupère des données tandis qu’une instruction plus ancienne calcule quelque chose, tandis qu’une instruction encore plus ancienne stocke ses résultats. Le problème survient lorsque vous avez déjà une instruction partiellement exécutée lorsque vous vous rendez compte qu’une instruction antérieure a provoqué une branche vers une autre partie de votre code. Maintenant, le pipeline doit être retiré et les performances en souffrent pendant le remplissage du pipeline. Tout ce qui a eu un effet doit s’inverser et tout le reste doit être jeté.
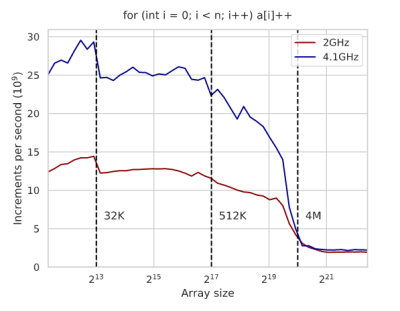

Comme vous vous en doutez, des techniques comme celle-ci dépendent de votre processeur et vous devrez comparer pour montrer ce qui se passe réellement. Le texte est plein de graphiques des temps d’exécution et d’une analyse du code assembleur généré pour x86 pour expliquer les résultats. Même quelque chose que vous pensez être un assez bon algorithme – comme la recherche binaire, par exemple, souffre des architectures modernes et vous pouvez améliorer ses performances avec quelques astuces. En fait, il est intéressant de noter que les astuces fonctionnent sur GCC, mais ne font aucune différence sur Clang. Encore une fois, vous devez mesurer ces choses.
Probablement 90 % d’entre nous n’auront jamais besoin d’utiliser le type d’optimisation que vous trouverez dans ce livre. Mais c’est un livre merveilleux si vous aimez résoudre des énigmes et analyser des détails complexes. Bien sûr, si vous avez besoin d’extraire ces microsecondes supplémentaires d’une boucle ou si vous écrivez une bibliothèque où les performances sont importantes, c’est peut-être le livre que vous recherchez. Bien qu’il ne couvre pas de nombreux processeurs différents, les idées et les techniques s’appliqueront à de nombreuses architectures de processeurs modernes. Vous aurez juste à faire le travail pour comprendre comment si vous utilisez un processeur différent.
Nous avons déjà examiné des éléments de ce genre. Pipeline, par exemple. Parfois, cependant, optimiser votre algorithme n’est pas aussi efficace que de simplement le changer pour un meilleur.