



































La plupart des lecteurs auront au moins une certaine familiarité avec les termes «Unicode» et «UTF-8», mais qu’y a-t-il vraiment derrière eux? À la base, ils font référence aux schémas de codage de caractères, également appelés jeux de caractères. C’est un concept qui remonte bien au-delà de l’ère des ordinateurs électroniques, à l’aube du télégraphe optique et de ses prédécesseurs. Dès le 18e siècle, il était nécessaire de transmettre rapidement des informations sur de grandes distances, ce qui était accompli à l’aide de ce que l’on appelle des codes télégraphiques. Ces informations codées à l’aide de moyens optiques, électriques et autres.
Au cours des centaines d’années qui se sont écoulées depuis l’invention du premier code télégraphique, aucun effort réel n’a été fait pour établir une normalisation internationale de ces schémas de codage, même les premières décennies de l’ère des téléimprimeurs et des ordinateurs personnels y apportant peu de changements. Même si EBCDIC (le codage de caractères 8 bits d’IBM démontré dans la carte perforée ci-dessus) et finalement ASCII ont fait des progrès, la nécessité d’encoder une collection croissante de caractères différents sans avoir à dépenser des quantités ridicules de stockage a été freinée par des solutions élégantes. .
Le développement d’Unicode a commencé à la fin des années 1980, lorsque l’échange croissant d’informations numériques à travers le monde a rendu le besoin d’un système de codage unique plus urgent qu’auparavant. De nos jours, Unicode nous permet non seulement d’utiliser un schéma de codage unique pour tout, du texte anglais de base au chinois traditionnel, vietnamien et même maya, mais aussi de petits pictogrammes appelés « emoji », du japonais « e » (絵) et « moji » (文字), littéralement «mot image».
Des livres de codes aux graphèmes
Dès l’époque de l’Empire romain, il était bien connu que la transmission rapide d’informations à travers une nation était essentielle. Pendant longtemps, cela signifiait avoir des messagers à cheval ou son équivalent, qui porteraient un message sur de grandes distances. Bien que des améliorations à ce système aient été imaginées dès le 4ème siècle avant JC sous la forme du télégraphe hydraulique par le grec ancien, ainsi que l’utilisation de feux de signalisation, ce n’est qu’au 18ème siècle que la transmission rapide d’informations sur de grandes les distances sont devenues monnaie courante.
Le télégraphe optique (également appelé «sémaphore») a été discuté en profondeur dans notre récent article sur l’histoire des communications optiques. Il se composait d’une ligne de stations relais, dont chacune était équipée d’un système surélevé de bras indicateurs pivotants (ou son équivalent) utilisé pour afficher le codage des caractères du code télégraphique. Le système français Chappe, qui a vu l’utilisation militaire française entre 1795 et les années 1850, était basé autour d’une traverse en bois avec deux extrémités mobiles (bras), dont chacune pouvait être déplacée dans l’une des sept positions. Avec quatre positions pour la barre transversale, cela a donné un 196 symboles théoriques (4x7x7). En pratique, ce nombre a été réduit à 92 ou 94 postes.
Ces points de code ont été utilisés non seulement pour le codage direct des caractères, mais surtout pour indiquer des lignes spécifiques dans un livre de codes. Cette dernière méthode signifiait que quelques points de code transférés pouvaient entraîner le message entier, ce qui accélérait la transmission et rendait l’interception des points de code inutile sans le livre de codes.
Amélioration du débit
Comme le télégraphe optique a été progressivement abandonné au profit du télégraphe électrique, cela signifiait que tout à coup, on ne se limitait pas aux encodages qui pouvaient être perçus par quelqu’un regardant à travers un télescope une tour de relais à proximité par temps acceptable. Avec deux appareils télégraphiques reliés par un fil métallique, tout à coup le moyen de communication était celui des tensions et des courants. Ce changement a conduit à une vague de nouveaux codes télégraphiques électriques, le code Morse international devenant finalement la norme internationale (à l’exception des États-Unis, qui ont continué à utiliser le code Morse américain en dehors de la radiotélégraphie) depuis son invention en Allemagne en 1848.
Le code Morse international présente l’avantage par rapport à son homologue américain en ce qu’il utilise plus de tirets que de points, ce qui ralentit les vitesses de transmission, mais améliore également la réception du message à l’autre bout de la ligne. Cela était essentiel lorsque de longs messages étaient transmis sur plusieurs kilomètres de câbles non blindés, par des opérateurs de niveaux de compétences variés.
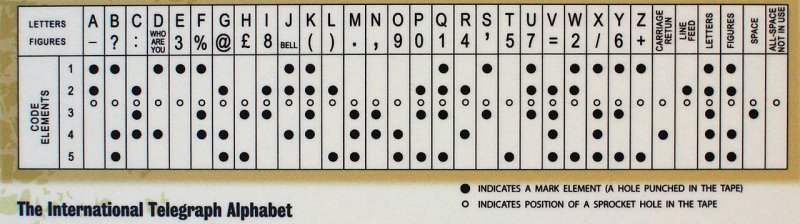
Au fur et à mesure que la technologie progressait, le télégraphe manuel a été remplacé en Occident par des télégraphes automatiques, qui utilisaient le code Baudot à 5 bits, ainsi que son code Murray dérivé, ce dernier basé sur l’utilisation de ruban de papier dans lequel des trous étaient percés. Le système de Murray permettait de préparer la bande du message à l’avance, puis de l’introduire dans un lecteur de bande pour une transmission automatique. Le code Baudot a formé la base de l’International Telegram Alphabet version 1 (ITA 1), avec un code Baudot-Murray modifié formant la base de l’ITA 2, qui a été utilisé jusque dans les années 1960.
Dans les années 1960, la limite de 5 bits par caractère n’était plus nécessaire ni souhaitable, ce qui a conduit au développement de l’ASCII 7 bits aux États-Unis et de normes comme JIS X 0201 (pour les caractères katakana japonais) en Asie. Combiné avec les téléimprimeurs qui étaient couramment utilisés à l’époque, cela permettait des messages texte assez compliqués, comprenant des caractères majuscules et minuscules, ainsi qu’une gamme de symboles à transmettre.

Au cours des années 1970 et au début des années 1980, les limites des encodages 7 et 8 bits comme l’ASCII étendu (par exemple ISO 8859-1 ou Latin 1) étaient suffisantes pour les besoins informatiques de base et de bureau. Même ainsi, le besoin d’amélioration était clair, car des tâches courantes telles que l’échange de documents et de textes numériques en Europe, par exemple, conduiraient souvent au chaos en raison de sa multitude d’encodages ISO 8859. La première étape pour résoudre ce problème est venue en 1991, sous la forme de l’Unicode 1.0 16 bits.
Dépassement de 16 bits
Ce qui est étonnant, c’est qu’en 16 bits seulement, Unicode a réussi à couvrir non seulement tous les systèmes d’écriture occidentaux, mais aussi de nombreux caractères chinois et une variété de symboles spécialisés, tels que ceux utilisés en mathématiques. Avec 16 bits permettant 216 = 65 536 points de code, les 7 129 caractères d’Unicode 1.0 s’adaptent facilement, mais au moment où Unicode 3.1 a été déployé en 2001, Unicode ne contenait pas moins de 94 140 caractères dans 41 scripts.
Actuellement, dans la version 13, Unicode contient un total général de 143 859 caractères, qui n’inclut pas les caractères de contrôle. Alors qu’à l’origine, Unicode était envisagé pour encoder uniquement les systèmes d’écriture qui étaient actuellement utilisés, au moment où Unicode 2.0 a été publié en 1996, il a été réalisé que cet objectif devrait être changé, pour permettre l’encodage de caractères même rares et historiques. Afin d’accomplir cela sans nécessairement exiger que chaque caractère soit codé en 32 bits, Unicode a changé non seulement pour encoder les caractères directement, mais également en utilisant leurs composants ou graphèmes.
Le concept est quelque peu similaire aux dessins vectoriels, où l’on ne spécifie pas chaque pixel, mais décrit à la place les éléments qui composent le dessin. Par conséquent, le codage Unicode Transformation Format 8 (UTF-8) prend en charge 231 points de code, la plupart des caractères du jeu de caractères Unicode actuel nécessitant généralement un ou deux octets chacun.
De nombreuses saveurs d’Unicode
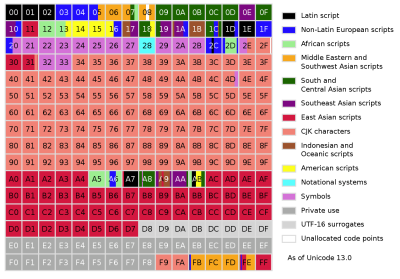
À ce stade, un certain nombre de personnes sont probablement au moins quelque peu confuses par les différents termes utilisés en ce qui concerne Unicode. Il est donc essentiel de noter ici que Unicode fait référence à la norme, les différents formats de transformation Unicode (UTF) étant les implémentations. UCS-2 et USC-4 sont respectivement des implémentations Unicode plus anciennes à 2 et 4 octets, UCS-4 étant identique à UTF-32 et UCS-2 ayant été remplacé par UTF-16.
UCS-2, en tant que première forme d’Unicode, a fait son chemin dans de nombreux systèmes d’exploitation des années 90, ce qui a fait du passage à UTF-16 l’option la moins perturbatrice. C’est pourquoi Windows, ainsi que MacOS, les gestionnaires de fenêtres comme KDE et les environnements d’exécution Java et .NET utilisent une représentation interne UTF-16.
UTF-32, comme son nom l’indique, encode chaque caractère en quatre octets. Bien que quelque peu gaspilleur, il est également simple et prévisible. Alors qu’en UTF-8, un caractère peut être de un à quatre octets, en UTF-32, déterminer le nombre de caractères dans une chaîne est aussi simple que de compter le nombre d’octets et de diviser par quatre. Cela a conduit à des compilateurs et à certains langages comme Python (éventuellement) permettant l’utilisation de UTF-32 pour représenter des chaînes Unicode.
De tous les formats Unicode, UTF-8 est cependant de loin le plus populaire. Cela a été largement motivé par le World Wide Web d’Internet, la plupart des sites Web servant leurs documents HTML au codage UTF-8. En raison de la disposition des différents plans de points de code dans UTF-8, Western et de nombreux autres systèmes d’écriture courants tiennent dans deux octets. Par rapport aux anciens encodages ISO 8859 et Shift JIS (8 à 16 bits), cela signifie qu’en fait, le même texte en UTF-8 ne prend pas plus d’espace qu’auparavant.
Des tours relais à Internet
Depuis ces premières années du passé de l’humanité, les technologies de la communication ont parcouru un long chemin. Finis les messagers, les tours relais et les petits bureaux de télégraphe. Même l’époque où les téléscripteurs étaient monnaie courante dans les bureaux du monde entier est aujourd’hui un souvenir qui s’estompe. À chaque étape, cependant, la nécessité d’encoder, de stocker et de transmettre des informations a été un thème central qui nous a poussés sans relâche au point où nous pouvons désormais transmettre instantanément un message à travers le monde, dans un encodage de caractères qui peut être décodé et compris. peu importe où l’on habite.
Pour ceux d’entre nous qui ont aimé basculer entre les encodages ISO 8859 dans nos clients de messagerie et nos navigateurs Web afin d’obtenir quelque chose qui se rapproche de la représentation textuelle originale, la prise en charge uniforme d’Unicode a été une bénédiction. Je peux imaginer un sentiment similaire parmi ceux qui se souviennent quand l’ASCII 7 bits (ou EBCDIC) était tout ce que l’on obtenait, ou appréciait de recevoir des documents numériques d’un bureau européen ou américain, pour souffrir de la confusion des jeux de caractères.
Même si Unicode n’est pas sans problèmes, il est difficile de ne pas regarder en arrière et de penser qu’il s’agit à tout le moins d’une amélioration décente par rapport à ce qui était auparavant. Voici encore trente ans d’Unicode.
(image d’en-tête: carte perforée avec l’alphabet occidental encodé en EBCDIC)

{kind=link}